





「ChatGPTで調べた答え、出典が書かれていなくて引用できない…」
AI検索ツールを使い始めたばかりのとき、そう感じたことはないでしょうか。
抄読会・症例検討の準備で「この情報の根拠は?」と聞かれても、ChatGPT単独では出典を確認しにくい場面は意外と多いはずです。
そこで活用したいのが、出典付きAI回答エンジン「Perplexity(パープレキシティ)」です。
今回は、Perplexityの基本操作(4ステップ)から、Pro Search・Academic Focus・Spacesの3機能の使い分け、強みと限界、Elicit・Consensus・PubMedとの役割分担まで、PT・OTが今日から使える形で解説します。
情報の信頼性について
・本記事はBRAIN代表/理学療法士の針谷が執筆しています(執筆者情報は記事最下部)。
・本記事はPerplexity公式仕様(2026年4月時点)および、Perplexityを評価したPubMed掲載のLLM比較研究のデータを基に解説しています。
自分で調べられるセラピストへ。
オンライン/PT・OT向け/BRAINアカデミー
本記事の結論
- Perplexityはすべての回答に出典リンクを付けるAI回答エンジンで、無料プランでも基本検索が無制限
- 4ステップで臨床疑問への出典付き回答が得られ、抄読会・症例検討・患者説明資料の準備に役立つ
- Pro Search・Academic Focus・Spacesの3機能を目的別に使い分けると、出典を辿りながら効率的にエビデンス収集できる
- Perplexity単独で文献検索を完結させない。PubMedによる厳密検索とElicit・Consensusによる論文単位の精査と組み合わせるのが正解
以下、詳しく解説していきます。
Perplexityとは?セラピストが使うべき3つの理由
Perplexity(パープレキシティ)は、すべての回答に出典リンク(Citations)を付けるAI回答エンジンです。
2022年8月にOpenAIの元研究者らによって設立され、ChatGPT・Claude・GPT-5など複数のLLMを組み合わせて回答を生成しつつ、各文に対応する出典を自動で表示します。
2026年に学術誌Southern Medical Journalに掲載された米国放射線学会(ACR)診断放射線専門医試験161問の比較研究では、Perplexity AIがGPT-4o・OpenEvidenceの中で最高の正答一致率(κ=0.883、P<0.001)を示したと報告されています(Aziz et al, 2026)。

セラピストの文献検索・情報収集ワークフローで、Perplexityが特に役立つのは以下の3つの場面です。
- 出典付き回答の取得:「この情報の根拠は?」と聞かれてもURLで即提示できる
- 診療ガイドライン・最新ニュースの横断検索:Webと学術データベースを同時に検索
- 抄読会・症例検討の前段階リサーチ:論文だけでなくガイドラインや報告書も含めて把握
そして、Perplexityの大きなメリットは「無料プランでも基本検索が無制限、Pro Searchも1日5回まで使える」ことです。
メールアドレスまたはGoogle・Appleアカウントを持っていれば、登録だけですぐに使い始められます。
※ EBPの基本的な考え方については、別記事「EBP/EBMとは|リハビリ臨床への活かし方|PT・OTのための実践ガイド」で詳しく解説しています。Perplexityは情報源の提示ステップを大幅に効率化します。
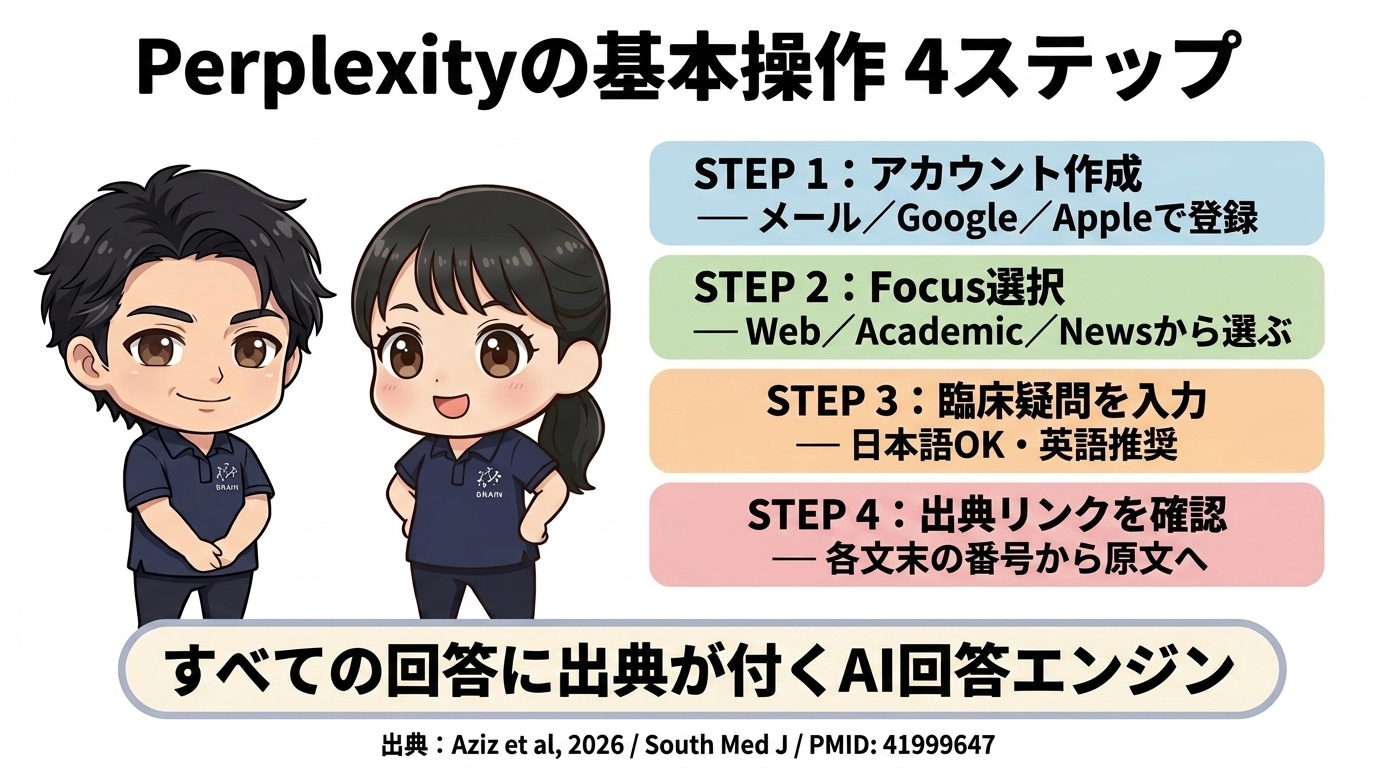
Perplexityの基本操作|4ステップで出典付き回答を得る
Perplexityを使い始める手順は、以下の4ステップです。
STEP1:アカウントを作成(メール/Google/Appleでログイン)
Perplexityの公式サイト(https://www.perplexity.ai/)にアクセスし、「Sign up」ボタンを押します。
メールアドレス・Google・Appleのいずれかで登録できます。
無料プランで基本検索が無制限、Pro Searchも1日5回まで使えます(2026年4月時点)。
STEP2:Focusで検索範囲を選ぶ(Web/Academic/News)
検索ボックスの下部にある「Focus」アイコンをクリックすると、検索範囲を選択できます。
- Web(デフォルト):すべてのウェブから検索
- Academic:査読論文を中心に検索(PubMed・Semantic Scholar・arXivなど)
- News:最新ニュース記事から検索
セラピストがエビデンス収集する場合は、「Academic」を選ぶのが基本です。
STEP3:臨床疑問を入力する(日本語OK・英語推奨)
検索ボックスに臨床疑問を入力します。
Perplexityは日本語入力にも対応していますが、Academic Focusで論文を検索する場合は英語入力の方が精度が高くなります。
What is the effectiveness of task-oriented training for upper limb function in chronic stroke patients?
質問文に対して、Perplexityが10〜30秒で出典付きの回答を生成します。
STEP4:出典リンクを確認・原文を読む
回答文の各文末に番号付きの出典リンク([1][2][3]…)が表示されます。
各リンクをクリックすると、引用元のWebサイト・論文・ニュース記事が新しいタブで開きます。
右側のサイドバーには、参照されたソース一覧(カード形式)も表示されます。
この4ステップを踏むだけで、臨床疑問への出典付き回答を数十秒で取得できるのがPerplexity最大の強みです。
Perplexityの3機能の使い分け
Perplexityには「Pro Search」「Academic Focus」「Spaces」の3つの主要機能があり、目的によって最適な機能が異なります。
Pro Search|複数のWeb検索を並列実行し統合レポート化
1つの臨床疑問に対して、複数のWeb検索を並列で実行し、矛盾を解消した上で統合レポートを生成する機能です。
処理に30〜60秒かかりますが、通常検索よりも詳細で網羅的な回答が得られます。
無料プランでは1日5回まで、Proプラン($20/月)以上で無制限になります。
Academic Focus|査読論文に特化した検索
検索範囲をPubMed・Semantic Scholar・arXivなどの査読論文に絞り込む機能です。
「臨床エビデンスだけを集めたい」「Web上の不確かな情報を排除したい」場合に使います。
無料プランでも利用可能です。
Spaces|検索結果を専門領域別に整理して継続活用
検索結果と参照ソースを専門領域・プロジェクト別にコレクションとして整理する機能です。
「上肢リハ」「歩行」「嚥下」などのSpacesを作成し、関連する検索を同じSpaceに保存して継続的にナレッジを蓄積できます。
※ Google ScholarとPubMedの違いについては、別記事「Google ScholarよりもPubMedを使うべき3つの理由」で詳しく解説しています。
Perplexityの料金プラン|無料・Pro・Max・Enterprise
Perplexityの料金プランは2026年4月時点で以下の通りです。
- 無料プラン:基本検索無制限+Pro Search 1日5回+Academic Focus利用可
- Pro:$20/月(年払い$200)。Pro Search無制限+全LLM選択可+ファイルアップロード無制限+月$5のAPIクレジット
- Max:$200/月。Pro機能+上位モデルへの優先アクセス
- Enterprise Pro:$40/seat/月。組織向け、SSO・管理機能付き
セラピストが個人で使うなら、まずは無料プランで1日5回のPro Searchを臨床疑問の検証に使うのが現実的です。
抄読会の主担当・症例レポート執筆など、頻繁に使う場合はPro($20/月)が費用対効果が高い選択肢になります。
Perplexityの強みと限界|AIに頼り切ってはいけない理由
Perplexity最大の強みは、「すべての回答に出典リンクが付き、根拠を即座に確認できる」点と、「比較研究で他の主要LLMを上回る正答率を示している」点にあります。
抄読会・症例検討・患者説明資料の準備で、極めて便利です。
ただし、Perplexityには明確な限界があり、最近のLLM比較研究で具体的に報告されています。
限界①:地域固有の臨床用語に弱い
2026年にJournal of Medical Imaging and Radiation Oncology誌に掲載された乳がん診療における3LLM比較研究では、ChatGPT・Gemini・Perplexityで31問の質問への臨床的妥当性を評価しました(Njunge et al, 2026)。
Perplexityの臨床的妥当性は90%(ChatGPT 97%、Gemini 87%)と高水準でしたが、西オーストラリア(WA)固有の用語を含む質問では不適切な回答が増加すると報告されました。
日本のセラピストが使う場合、「介護保険」「リハビリテーション科」「PT・OT・ST」など日本固有の医療用語では、米国・英国の文脈で回答が生成される可能性があります。
限界②:プロンプトを工夫しないと回答品質が下がる
2026年にJournal of the American College of Clinical Pharmacy誌に発表された6種AIツール比較研究では、Perplexity・Gemini・ChatGPT・Copilot・Llama・Claudeで薬剤モノグラフ作成を評価(Sibbesen et al, 2026)。
広範な初期プロンプトではすべてのツールが「曖昧・不完全・不正確」な回答となり、セクション別の絞り込みプロンプトで初めて品質が向上すると結論されました。
「○○について教えて」と漠然と聞くのではなく、「○○の効果量・対象・介入期間を分けて」と具体化することが必須です。
限界③:標準化された記述スタイルに偏る傾向がある
2025年にBrazilian Dental Journalに発表されたAIツール比較研究では、Elicit・Perplexity・Consensus・ChatGPT・Grammarlyを比較し、Perplexityを含むAI出力は技術的不正確さや過度に標準化された記述スタイルといった限界を抱えると報告されています(Granjeiro et al, 2025)。
Perplexityの解説文をそのままコピペで使うと、文章のクセが似通ってしまい、独自の臨床的考察が薄まる恐れがあります。
2025年にResearch Synthesis Methods誌で発表された生成AI×SR研究の系統的レビューでは、19研究の解析から生成AIは検索段階で68〜96%(中央値91%)の論文を取り逃し、誤除外率は1〜83%(中央値28%)と報告されています(Clark et al, 2025)。
つまり、AIツール全般に「論文の取り逃し」と「誤除外」のリスクがあるため、人間によるダブルチェックは必須です。
関連する内部記事として「有料の英語論文を無料で入手する4つの方法」も併せて参照すると、Perplexityで見つけた論文を効率的に全文入手できます。
Elicit・Consensus・PubMedとの使い分け|文献検索ワークフローの全体像
「Perplexityだけで全部できるのでは?」と思いがちですが、Elicit・Consensus・PubMedにはそれぞれ得意領域があります。
4つのツールは「使う場面が違う」ので、どれか1つに絞るのではなく、用途に応じて使い分けるのが正解です。
- Perplexity:出典付きの素早い回答を得る(Web+Academic横断、ガイドライン・ニュース含む)
- PubMed:厳密な検索式で網羅的に集める(最終的なエビデンス採用判断はここで行う)
- Elicit:研究の傾向・方向性確認に使う(PICOから関連論文を広く拾い、対象・方法・結果を表形式で比較)
- Consensus:Yes/No判定に使う(介入の効果有無を素早く把握、SDM資料用)
つまり、文献検索ワークフローの「出典付き回答:Perplexity」「厳密検索:PubMed」「広く拾う:Elicit」「Yes/No判定:Consensus」と役割を分担すると、効率が一気に上がります。
2025年にBrazilian Dental Journalに発表されたAIツール比較研究でも、Elicit・Perplexity・Consensus・ChatGPT・Grammarlyのそれぞれが文献分析ワークフローの異なる段階で機能を発揮することが報告されています(Granjeiro et al, 2025)。
各ツールの具体的な使い方は、別記事で詳しく解説しています:
→ PubMedの使い方|PT・OTのための完全ガイド|検索手順を初心者向けに解説
→ Elicitの使い方|AIで関連文献を一気に把握する4ステップ|PT・OT実践ガイド
→ Consensusの使い方|Yes/No判定とConsensus MeterでEBPを加速する4ステップ|PT・OT実践ガイド
→ Semantic Scholarの使い方|TLDR要約と引用ネットワークで関連論文を芋づる式に探す|PT・OT実践ガイド
BRAINでのPerplexity活用事例|出典提示型リサーチでの使い方
BRAIN(株式会社BRAINが運営する脳卒中専門リハビリ施設)でも、Perplexityをセラピスト全員で活用しています。
具体的には、以下のような使い方をしています。
- 診療ガイドライン・公式声明の確認:脳卒中ガイドライン・各学会の最新推奨を出典付きで素早く把握する
- 患者説明資料の根拠確認:「TMSの安全性は?」など患者からの質問に対して出典URLとセットで回答する
- Spacesで領域別ナレッジ蓄積:「上肢リハ」「歩行」「嚥下」のSpaceに継続的に保存し、新人セラピスト教育に活用
特に重要な運用ルールは、Perplexityの回答は必ず出典リンクを開いて原文を確認するという点です。
2025年にValue in Health誌に発表された生成AI×SR研究の系統的レビューでは、30研究の解析から、生成AIはPICO策定・データ抽出には有効だが、文献検索・研究選択での単独運用は非推奨と結論されています(Rashid et al, 2025)。
この知見は、BRAINでの「Perplexityは出典の素早い特定、最終判断はセラピストが原文を読んで行う」という運用方針の科学的裏付けになっています。
よくある質問(FAQ)
Q1:Perplexityは完全無料で使えますか?
無料プランでも基本検索は無制限、Pro Searchも1日5回まで使えます。
有料プラン(Pro $20/月)にすると、Pro Searchが無制限になり、ファイルアップロード制限も外れます。
まずは無料プランで試してみて、業務に使えるか確認してから有料化を検討するのがおすすめです。
Q2:日本語で検索してもいいですか?
はい、Perplexityは日本語入力に対応しており、日本語で回答も生成されます。
ただしAcademic Focusで論文を検索する場合は、収録論文の多くが英語のため、英語入力の方が圧倒的に精度が高くなります。
ChatGPTやDeepL翻訳を使ってキーワード・臨床疑問を英訳してから入力しましょう。
Q3:PerplexityとChatGPTはどちらを使うべきですか?
用途によって使い分けます。
「出典付きの根拠ある回答が必要」な場合(抄読会・症例検討・患者説明資料)はPerplexity。
「文章の言い換え・PICOの整理・英訳」など出典が不要な作業はChatGPTが向いています。
2026年の放射線学会試験比較研究では、PerplexityがGPT-4o・OpenEvidenceを上回る正答一致率を示しました(PMID 41999647)。
Q4:Perplexityが提示した出典はそのまま臨床判断に使っていいですか?
そのまま使う前に、必ず出典リンクを開いて原文を確認してください。
2026年の乳がんLLM比較研究では、Perplexityの臨床的妥当性は90%でしたが、地域固有の用語では不適切な回答が増加することが報告されています(PMID 41937254)。
Perplexityの出力は「出典への素早い案内」と捉え、論文の核心となる数値・対象患者・効果量は原文を見て確認するのが大原則です。
Q5:施設のセキュリティポリシーで使えるか不安です
所属施設の情報システム部門・コンプライアンス担当に必ず事前確認してください。
Perplexityに入力するのは「臨床疑問」(公開済みの研究テーマ)であり、患者個人情報を含めなければ問題ない施設が多いですが、施設ごとにポリシーが異なるため確認は必須です。
カルテ情報・患者氏名・生年月日などの個人情報は、絶対に入力しないでください。
本記事のまとめ
- Perplexityはメールアドレスだけで無料利用できる、出典付きAI回答エンジン
- 4ステップ(アカウント作成→Focus選択→質問入力→出典リンク確認)で出典付きの臨床疑問への回答を数十秒で取得できる
- Pro Search・Academic Focus・Spacesの3機能を目的別に使い分けることで、ガイドライン確認・患者説明資料・継続的ナレッジ蓄積の効率が一気に上がる
- Perplexity単独では地域固有用語への弱さ・標準化された記述スタイルの限界があるため、PubMedによる厳密検索とElicit・Consensusによる論文単位の精査と組み合わせ、最終判断は人間が行うのが大原則
本記事の内容が、出典付きで素早くエビデンスを集めたい・ガイドライン情報を効率的に確認したいセラピストの役に立てましたら幸いです。
参考文献
Aziz R, Stewart S, Liscomb R, et al. Performance of Large Language Models on Diagnostic Radiology Board-Style Questions: A Comparative Evaluation of GPT-4o, Perplexity AI, and OpenEvidence. South Med J. 2026;119(4):191-194. PMID: 41999647
Sibbesen JB, Trickett H, Yzaguirre S. An Evaluation of Six Artificial Intelligence Tools for Formulary Management. J Am Coll Clin Pharm. 2026;9(2):e70172. PMID: 42009480
Njunge M, Huang Y, Li R, et al. Assessing the Safety and Clinical Appropriateness of Breast Cancer Advice From Consumer-Grade Large Language Models. J Med Imaging Radiat Oncol. 2026. PMID: 41937254
Granjeiro JM, Cury AADB, Cury JA, et al. The future of scientific writing: AI tools, benefits, and ethical implications. Braz Dent J. 2025;36:e256471. PMID: 40197923
Cao J, Wu Z, Wu Z, et al. The reliability and readability of large language models in answering patient questions on maintenance hemodialysis: A comparative study. Digit Health. 2026;12:20552076261435836. PMID: 41883541
Ozturk GA, Tumer EG, Çoban FSK, et al. AI chatbots for patient education in localized prostate cancer radiotherapy: A comparative quality and readability analysis. Patient Educ Couns. 2026;149:109594. PMID: 41875785
Al-Khanaty A, Santucci J, Hennes D, et al. Quality and Usability of Prostate Cancer Information Generated by Artificial Intelligence Chatbots: A Comparative Analysis. Cancers (Basel). 2026;18(6):906. PMID: 41899512
Icen M, Temur KT. Comparative diagnostic accuracy of multiple large language models in oral and maxillofacial radiology specialty examinations: a 13-year analysis of performance and topic trends. BMC Oral Health. 2026. PMID: 41917901
Clark J, Barton B, Albarqouni L, et al. Generative artificial intelligence use in evidence synthesis: a systematic review. Res Synth Methods. 2025. PMID: 41626912
Rashid M, Yi CS, Sathapanasiri T, et al. Role of generative artificial intelligence in assisting systematic review process in health research: a systematic review. Value Health. 2025. PMID: 40848037
Gainey CS, Shroff H, Fix OK. Artificial intelligence tools for GI research: a practical guide. Clin Gastroenterol Hepatol. 2026. PMID: 41935592
自分で調べられるセラピストへ。
オンライン/PT・OT向け/BRAINアカデミー

書籍|文献検索の超基本
「先輩に聞けばいい」から卒業しませんか?
本書は、PT・OT・STが最短で文献検索を身につけるための一冊です。172ページ+40本の動画で、PubMed検索からAI活用まで実践的に学べます。ChatGPT、Elicit、Semantic ScholarなどのAIツールを”なんとなく使う”のではなく、正しく臨床に活かす方法を体系的に解説。文献検索は、早く身につけた人が圧倒的に伸びます。エビデンスを自分で調べられるセラピストになりませんか?




