





「PubMedで集めた論文の山を、AIで一気に要約できないか?」
臨床業務に追われるPT・OT・STなら、一度は考えたことがあるはずです。
2024年以降、論文を要約してくれるAIツールは急速に増えました。ChatGPT・Elicit・NotebookLM・Consensus・Perplexityなど、無料〜安価で使えるものが揃っています。
ただし、便利な反面、AIに任せきりにすると重要な論文を見落とすリスクがあることも、2025年のシステマティックレビューで明らかになってきました。
本記事では、論文要約に使える5つのAIツールを比較し、PT・OT・STが今日から実務で使える「ツールの選び方」と「AI要約の落とし穴」を解説します。
情報の信頼性について
・本記事はBRAIN代表/理学療法士の針谷が執筆しています(執筆者情報は記事最下部)。
・本記事は、生成AIによる文献検索・要約の精度を検証したシステマティックレビュー(Clark et al, 2025; Rashid et al, 2025)と、5つのAIツールの公式仕様に基づいて解説しています。
自分で調べられるセラピストへ。
オンライン/PT・OT向け/BRAINアカデミー
本記事の結論
- 論文をAIで要約する用途には、ChatGPT・Elicit・NotebookLM・Consensus・Perplexityの5ツールを使い分けるのが現実的
- 「前段階の整理→広く拾う→深く読む」の3フェーズでツールを切り替えると、文献検索の時間を最大75%削減できる(Nykvist et al, 2025)
- ただし、AIだけに任せると中央値91%の論文を取り逃す(Clark et al, 2025)。最終判断は必ずPT・OT・ST自身で行う
以下、5ツールの比較と臨床現場での使い方を詳しく解説します。
なぜAI要約がEBP実践に必要なのか
EBP(Evidence-Based Practice)を臨床に持ち込もうとすると、必ずぶつかる壁があります。
「論文を読む時間が確保できない」という壁です。
PubMedに収載されている論文数は年々増加しており、リハビリ領域だけでも年間数千本のRCT・SRが新しく発表されます。担当患者さんの臨床疑問1つを解決するために、50〜100本の論文を1次スクリーニング(タイトルと抄録のチェック)し、そこから10〜20本を2次スクリーニング(本文の精読)するのは、現実的には丸2日〜1週間かかる作業です。
この時間を圧縮するために、AIによる論文要約は強力な武器になります。
2025年に学術誌J Am Med Inform Assocで発表された大規模検証研究では、6種類のLLM(GPT-3.5/4/4o・Llama 3・Gemini 1.5 Pro・Claude Sonnet 3.5)を23件のCochraneレビュー(合計119,695本の論文)で評価し、LLMと人間のアンサンブル(協働)でスクリーニング作業量を37.55〜99.11%削減できたと報告されています(Sanghera et al, 2025)。
また、環境系SR(n=12,000件規模)でGPT-4を検証した研究でも、リコール95%を維持しつつスクリーニング時間を75%削減できたと報告されています(Nykvist et al, 2025)。
つまり、AI要約を上手く使うことができれば、「論文を読む時間がない」という言い訳が成立しない状況になりつつあります。
論文をAIで要約する5ツールの全体比較
論文要約に使えるAIツールはいくつもありますが、PT・OT・STの実務で押さえておきたいのは以下の5つです。
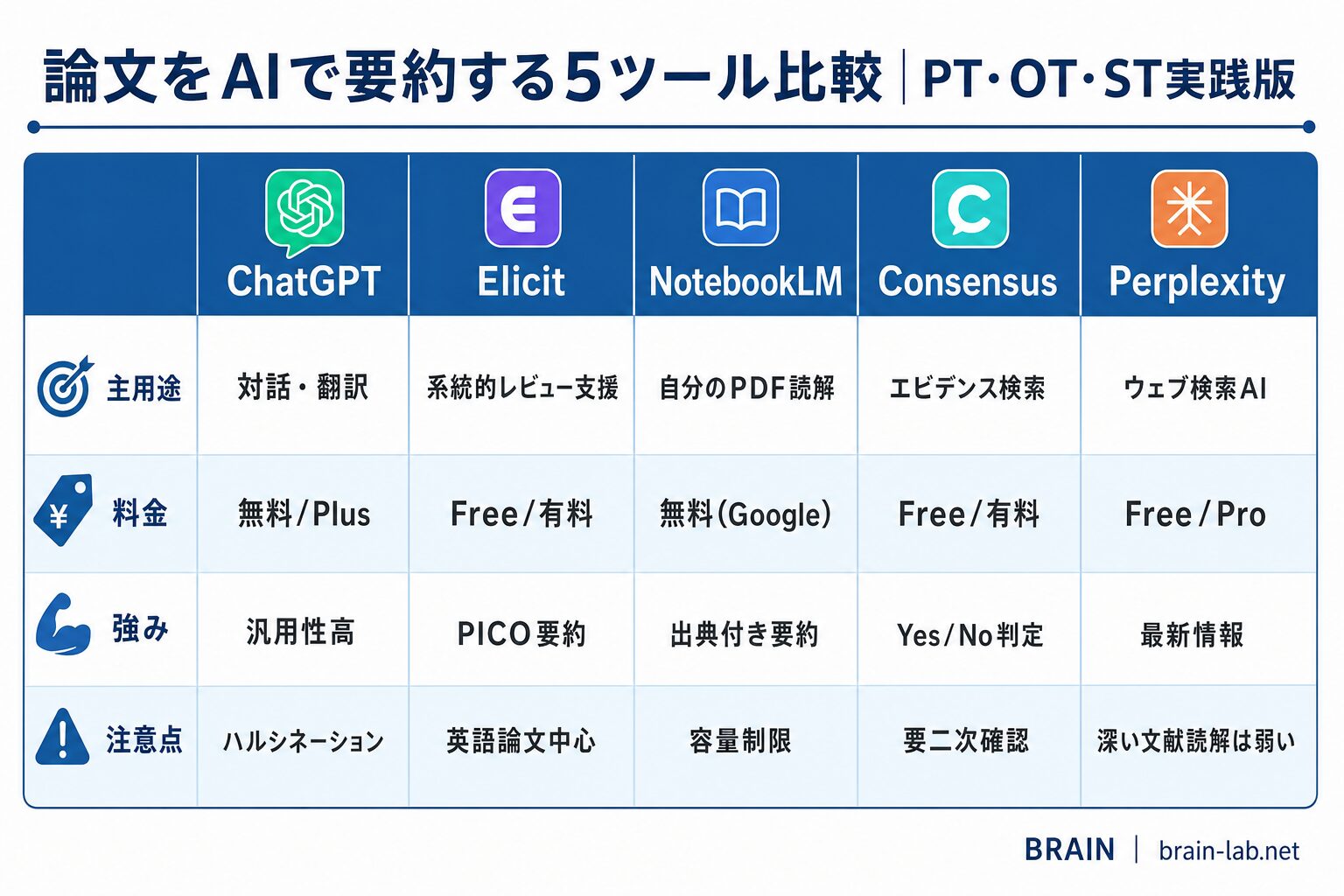
それぞれ得意領域が異なるため、「どれか1つに絞る」のではなく「場面ごとに使い分ける」のが正解です。
① ChatGPT|PICO定式化と検索式作成の前段階
ChatGPT(OpenAI社)は、文献検索の前段階で力を発揮します。具体的には、臨床疑問のPICO定式化、検索式の作成、MeSH用語の提案、研究デザインの選定などです。
「いきなり論文を要約させる」よりも、「これから検索する前の準備」をChatGPTに手伝ってもらうのが、最も時間対効果が高い使い方です。
料金:GPT-4o系の利用は月額20ドル(ChatGPT Plus)が現実的。無料版は応答精度が劣ります。
② Elicit|文献検索の幅出しと関連論文の俯瞰
Elicitは、PICOから関連論文を一気に広く拾うのに優れたAI文献検索ツールです。Semantic Scholarのデータベースを基盤としているため、PubMed単独では拾いきれない論文を発見できます。
抽象的な質問(例:「脳卒中後の重度上肢麻痺に有効な介入は?」)を投げると、関連論文を一覧化し、それぞれの結論を自動要約してくれます。
料金:無料プランあり、有料プランは月額12ドル〜。詳しくは Elicitの使い方|AIで関連文献を一気に把握する4ステップ で解説しています。
③ NotebookLM|手元のPDFを深く読み込む
NotebookLM(Google社)は、すでに集めた論文PDFを深く読み込む用途に最も強いツールです。1ノートブックあたり最大50本のPDF・URL・テキストをアップロードでき、それらを根拠に質問応答・要約・データ抽出を行います。
2026年にPsychiatry誌で発表された検証研究では、Army STARRS関連の22本の論文をNotebookLMにアップロードし、プロンプト設計次第で文献要約・質問応答が有効に機能する一方で、新規論文の検索はできないこと・引用の正確性に弱点があることが報告されています(Shor & Greene, 2026)。
料金:Googleアカウントがあれば無料で利用可能。詳しくは NotebookLMで論文を読む|PT・OTのスクリーニング負担を5分の1にする活用ガイド を参照してください。
④ Consensus|Yes/No判定で結論を一目で把握
Consensusは、臨床疑問に対する論文の結論を「Yes/No/Mixed」で集約してくれるAI検索エンジンです。約2億本以上の論文を対象に、Consensus Meterで研究全体の傾向を可視化します。
「ミラーセラピーは脳卒中後の上肢麻痺に有効か?」のような Yes/No 型の質問に対して、Yes寄りの論文・No寄りの論文の割合を即座に提示してくれるため、エビデンスの方向性を素早く確認できます。
料金:無料プランあり、有料プランは月額8.99ドル〜。詳しくは Consensusの使い方|Yes/No判定とConsensus MeterでEBPを加速する4ステップ を参照してください。
⑤ Perplexity|出典付きで臨床疑問を即座に解決
Perplexityは、ChatGPTのような対話インターフェイスに「出典リンクの自動付与」を組み合わせたAI検索エンジンです。質問に対する回答の各文章に、根拠となる論文やWebページのリンクが付くため、即座に出典確認ができます。
「脳卒中後うつの有病率は?」のような事実確認系の臨床疑問に対して、最速で「答え+根拠」を取れるのが強みです。
料金:無料プランあり、有料プラン(Pro)は月額20ドル〜。詳しくは Perplexityの使い方|出典付きAI回答エンジンで臨床疑問を即座に解決する4ステップ を参照してください。
場面別ベストユース|AI論文要約の使い分け
5ツールを「どの場面でどれを使うか」を整理すると、以下のようになります。
場面①:臨床疑問のPICO定式化・検索式作成 → ChatGPT
担当患者さんから生まれた漠然とした疑問を、検索可能なPICO(Patient・Intervention・Comparison・Outcome)の形に整える段階です。
ChatGPTに「以下の臨床疑問をPICOに整理して、PubMed検索式も作ってください」と指示するだけで、検索式のたたき台を10分以内に得られます。
場面②:論文をなるべく広く拾う → Elicit + Consensus + Perplexity
PubMed単独だと、検索式のキーワードに依存して論文を取り逃すリスクがあります。Elicit・Consensus・Perplexityを併用することで、検索の網を広げられます。
特にElicitはSemantic Scholar基盤、Consensusは約2億本のDBを対象としているため、PubMedとは異なる切り口で関連論文を出してくれます。
さらに、引用ネットワークを辿って関連論文を芋づる式に発見したい場合は、Semantic Scholar単独での利用も有効です。詳しくは Semantic Scholarの使い方|TLDR要約と引用ネットワークで関連論文を芋づる式に探す を参照してください。
場面③:絞り込んだ論文を深く読む → NotebookLM
1次スクリーニングで残した10〜20本のPDFをNotebookLMにアップロードし、データ抽出・批判的吟味を進める段階です。
NotebookLMは「アップロードした文献だけを根拠に回答する」仕組みのため、ChatGPT等よりハルシネーション(事実と異なる出力)が少ないのが強みです(Shor & Greene, 2026)。
2024年にJ Med Internet Res誌で発表された3層スクリーニング戦略の検証研究では、双極性障害治療の2件のSR(論文計4,527本)でGPT-3.5/4を活用し、感度0.962/0.943・特異度0.996/0.855を達成しています(Matsui et al, 2024)。NotebookLMもGemini基盤のLLMであり、同様の運用設計が応用可能です。
場面④:事実確認・出典探し → Perplexity
「脳卒中後うつの有病率は?」のような単発の事実確認には、Perplexityが最速です。出典リンクが各文章に付くため、エビデンスの裏取りもその場でできます。
ただし、Perplexityの出典は論文以外のWebページも含むため、医学情報として扱う場合はリンク先の信頼性(査読論文か、公的機関か)を必ず確認してください。
BRAINの判断!
BRAINでは、5ツールを「ChatGPT→Elicit/Consensus/Perplexity→NotebookLM」の順で組み合わせています。最初に方向性を整理し、次に広く拾い、最後に深く読む流れにすると、1つの臨床疑問を解決するのに丸1日かかっていた作業が半日に短縮できます。
AI論文要約の落とし穴と回避策
AI要約は便利ですが、過信すると重要なエビデンスを見落とします。直近のシステマティックレビュー研究で明らかになった落とし穴を3つ紹介します。
落とし穴①:AI検索だけだと中央値91%の論文を取り逃す
2025年にResearch Synthesis Methods誌で発表された19研究の系統的レビューでは、生成AIを使った文献検索・選択で中央値28%の論文が誤って除外され、検索段階で中央値91%の論文を取り逃したと報告されています(Clark et al, 2025)。
これは、AIによる文献検索・スクリーニングを単独で行うと、SR・メタアナリシス級のエビデンス統合では致命的な抜けが生じることを意味します。
回避策:AI検索の結果を「すべて」ではなく「ベースライン」と捉え、PubMed検索+ハンドサーチを必ず併用することが必須です。
落とし穴②:ハルシネーション(事実と異なる出力)
ChatGPT・Perplexityは、稀に存在しない論文・著者・PMIDを生成することがあります(ハルシネーション)。
2025年にValue Health誌で発表された生成AIによるSRプロセス支援の系統的レビューでは、生成AIの性能はモデル・タスク・設定によって大きく変動し、運用フレームワークが未整備であることが指摘されています(Rashid et al, 2025)。
回避策:AIが出力したPMIDは必ずPubMedで存在確認し、引用するデータ(数値・サンプル数・効果量)は原文に戻って確認してください。NotebookLMは「アップロードした文献だけを根拠に回答する」設計のため、ChatGPT等よりハルシネーションが起こりにくい仕組みです。
落とし穴③:研究の質を判定できない
AIは論文の内容を要約できますが、研究デザインの妥当性・バイアスリスク・臨床応用の限界を独立して判定する能力は限定的です。
2025年にJ Am Med Inform Assoc誌で発表された大規模検証研究でも、LLM単独ではなく「LLM+人間」のアンサンブル運用でこそ、作業量削減と精度維持が両立できると示されています(Sanghera et al, 2025)。
回避策:研究の質判定(バイアスリスク評価・効果量の臨床的意義)は、必ずPT・OT・ST自身が行うことが大原則です。
AI要約の限界をより体系的に学びたい方は 文献検索AIの落とし穴|PT・OTが押さえるべき7つの限界と運用フレームワーク も併せて参照してください。
BRAINの臨床現場での運用フロー(3ステップ)
BRAIN(脳卒中専門の保険外リハビリ施設)でも、5ツールを組み合わせた論文要約ワークフローをセラピスト全員で運用しています。実際の3ステップを紹介します。
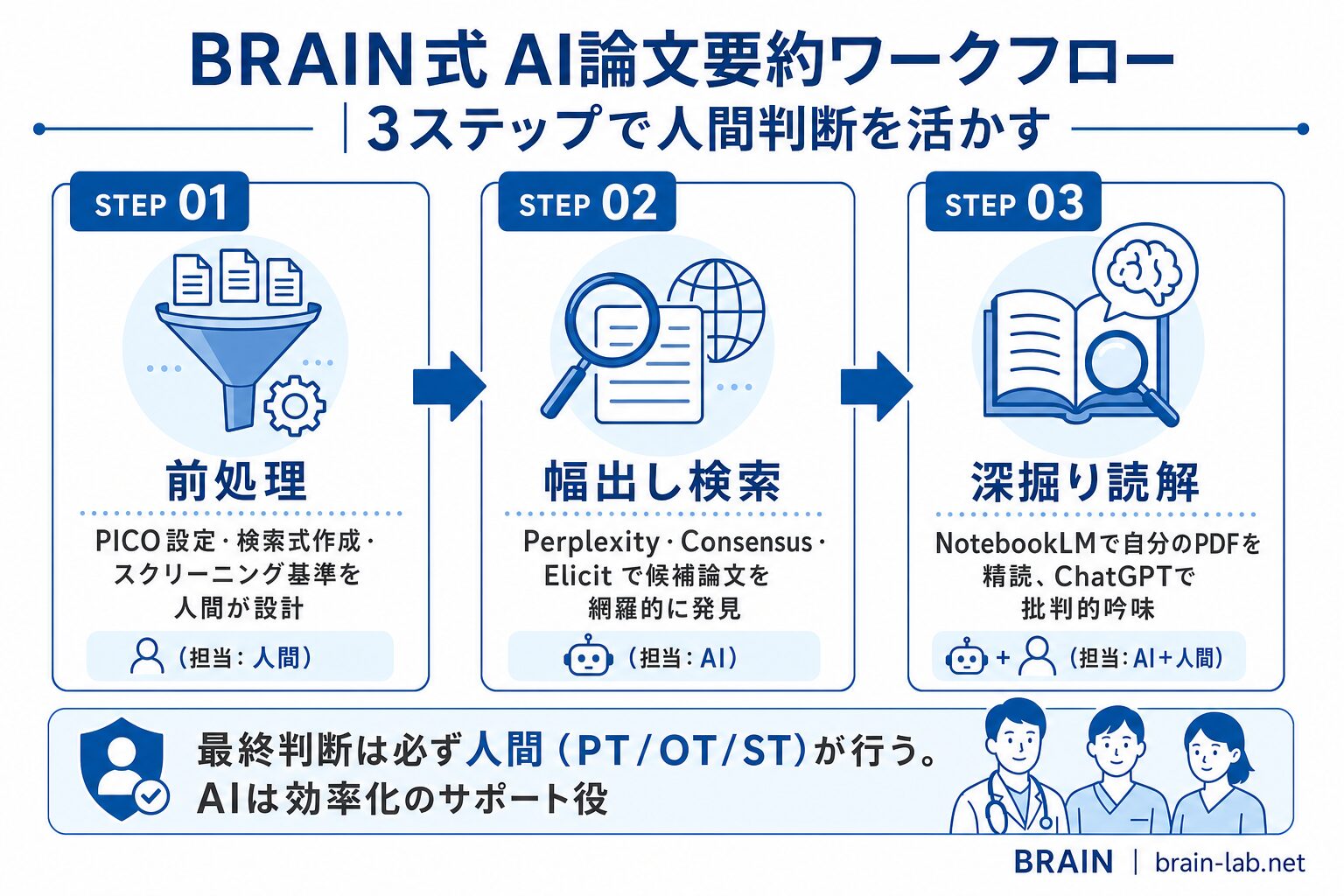
STEP1:ChatGPTで前処理(PICO定式化+検索式作成)
担当患者さんから生まれた疑問(例:「FMA-UE 18点の重度上肢麻痺に課題指向型訓練は有効か?」)を、ChatGPTにPICO形式へ整えてもらいます。同時にPubMedの検索式も生成してもらい、たたき台を作ります。
所要時間:5〜10分。これだけで「何を検索すべきか」が明確になります。
STEP2:Elicit/Consensus/Perplexityで幅出し検索
PubMedでの本検索と並行して、ElicitとConsensusで関連論文を広く拾います。Perplexityは事実確認(有病率・疫学データ)に使い分けます。
所要時間:15〜30分。50〜100本のタイトルと抄録を一気にスクリーニングできます。
STEP3:NotebookLMで深掘り読解とデータ抽出
STEP2で絞り込んだ10〜20本のPDFをNotebookLMにアップロードし、2次スクリーニング・データ抽出・批判的吟味を進めます。
所要時間:1〜2時間。これまで丸1日かかっていた作業が半分以下に圧縮されます。
最終的な判定(採用/除外、研究の質、臨床応用可否)は必ず人間のPT・OT・STが行います。
BRAINの判断!
BRAINでは、新人セラピストにこの3ステップを最初の1ヶ月で習得してもらいます。AIに任せるのではなく「AIと共同作業する」感覚を身につけることが、長期的にEBPを継続するためのカギです。
2026年にArch Phys Med Rehabil誌で発表されたCLARITY(Clinical Literature Analysis and Review using Interpretive Transparency)フレームワークでは、リハビリテーション領域のAI支援エビデンス合成において、教育的スキャフォールドを設けて段階的に習得することの重要性が指摘されており(Ball et al, 2026)、BRAINの段階的習得プロセスと方向性が一致しています。
よくある質問(FAQ)
Q1:5ツール全部を有料契約する必要がありますか?
いいえ、すべてに無料プランがあります。まずは無料で試してみて、業務頻度が高いものだけ有料契約するのが現実的です。
BRAINでは、ChatGPT Plus(月額20ドル)とNotebookLM Plus(任意)の2つだけを有料契約し、残りは無料プランで運用しています。
Q2:英語が苦手でも論文要約に使えますか?
使えます。すべてのツールに「日本語で要約してください」と指示すれば、日本語で回答が返ってきます。専門用語の翻訳精度も実用レベルです。
Q3:施設のセキュリティポリシーで使えるか不安です
所属施設の情報システム部門に必ず事前確認してください。論文PDFやテキストデータ(公開済みの研究情報)であれば問題ない施設が多いですが、患者の個人情報を含むファイルは絶対にアップロード禁止です。
Q4:AIの要約をそのまま臨床判断に使っていいですか?
原則として「下調べ」と捉え、最終判断は人間が行ってください。AI単独では中央値91%の論文を取り逃すというSRエビデンスがあり(Clark et al, 2025)、重要な研究を見落とすリスクは無視できません。
Q5:もっと体系的にAI×文献検索を学ぶには?
BRAINアカデミー(オンライン学習プログラム)や、書籍『文献検索の超基本』(針谷遼著)の第9章で、5ツールを含むAI活用全体像を体系的に学べます。詳細は記事末尾のリンクからご確認ください。
本記事のまとめ
- 論文をAIで要約する用途には、ChatGPT・Elicit・NotebookLM・Consensus・Perplexityの5ツールを組み合わせるのが現実的
- 「前段階の整理(ChatGPT)→ 広く拾う(Elicit/Consensus/Perplexity)→ 深く読む(NotebookLM)」の3フェーズで運用すると、文献検索の所要時間が大幅に短縮できる
- AI単独だと中央値91%の論文を取り逃す(Clark et al, 2025)。最終判断は必ずPT・OT・ST自身で行うことが大原則
- 個人情報のアップロード禁止・原文確認の徹底・研究の質判定は人間が担当の3点は必ず守る
本記事の内容が、論文を読む時間に悩んでいるPT・OT・STの役に立てましたら幸いです。
参考文献
Clark J, Barton B, Albarqouni L, et al. Generative artificial intelligence use in evidence synthesis: A systematic review. Res Synth Methods. 2025;16(4):601-619. PMID: 41626912
Sanghera R, Thirunavukarasu AJ, El Khoury M, et al. High-performance automated abstract screening with large language model ensembles. J Am Med Inform Assoc. 2025;32(5):893-904. PMID: 40119675
Matsui K, Utsumi T, Aoki Y, et al. Human-Comparable Sensitivity of Large Language Models in Identifying Eligible Studies Through Title and Abstract Screening: 3-Layer Strategy Using GPT-3.5 and GPT-4 for Systematic Reviews. J Med Internet Res. 2024;26:e52758. PMID: 39151163
Nykvist B, Macura B, Xylia M, et al. Testing the utility of GPT for title and abstract screening in environmental systematic evidence synthesis. Environ Evid. 2025;14(1):7. PMID: 40270055
Rashid M, Yi CS, Sathapanasiri T, et al. Role of Generative Artificial Intelligence in Assisting Systematic Review Process in Health Research: A Systematic Review. Value Health. 2025;28(11):1665-1682. PMID: 40848037
Shor R, Greene EA, Sumberg L. AI Tools in Academia: Evaluating NotebookLM as a Tool for Conducting Literature Reviews. Psychiatry. 2026;89(1):82-91. PMID: 40875632
Hsu CH, Hsu CL, Tsou CH, et al. Improving Clinical Decision-Making in Treating Airway Diseases With an Expert System Built Upon the Free AI Tool Google NotebookLM. JMIR Med Inform. 2026;14:e78567. PMID: 41483468
Landschaft A, Antweiler D, Mackay S, et al. Implementation and evaluation of an additional GPT-4-based reviewer in PRISMA-based medical systematic literature reviews. Int J Med Inform. 2024;189:105531. PMID: 38943806
Khraisha Q, Put S, Kappenberg J, et al. Can large language models replace humans in systematic reviews? Evaluating GPT-4’s efficacy in screening and extracting data from peer-reviewed and grey literature in multiple languages. Res Synth Methods. 2024;15(4):616-626. PMID: 38484744
Guo E, Gupta M, Deng J, et al. Automated Paper Screening for Clinical Reviews Using Large Language Models: Data Analysis Study. J Med Internet Res. 2024;26:e48996. PMID: 38214966
Li Y, Datta S, Rastegar-Mojarad M, et al. Enhancing systematic literature reviews with generative artificial intelligence: development, applications, and performance evaluation. J Am Med Inform Assoc. 2025;32(4):616-625. PMID: 40036547
Ball AM, Perreault T, Dommerholt J, et al. Clinical Literature Analysis and Review using Interpretive Transparency (CLARITY): An Exploratory Scaffold for Educational Engagement With Artificial Assistance (AI)-Assisted Evidence Synthesis in Rehabilitation. Arch Phys Med Rehabil. 2026. PMID: 41747878
自分で調べられるセラピストへ。
オンライン/PT・OT向け/BRAINアカデミー

書籍|文献検索の超基本
「先輩に聞けばいい」から卒業しませんか?
本書は、PT・OT・STが最短で文献検索を身につけるための一冊です。172ページ+40本の動画で、PubMed検索からAI活用まで実践的に学べます。第9章ではChatGPT、Elicit、NotebookLM、Consensus、PerplexityなどのAIツールを”なんとなく使う”のではなく、正しく臨床に活かす方法を体系的に解説。文献検索は、早く身につけた人が圧倒的に伸びます。エビデンスを自分で調べられるセラピストになりませんか?




